(Lack of) Statistical Thinking in the NYT
The New York Times yesterday (Nov 2, 2023) had a story and podcast about the "only [US county] that has voted for the winner of the [US] presidential race every year since 1980."
They write:

"Prediction," you say? That will awaken any quant!
Also, it's about Clallam County, Washington — here in my home state. To paraphrase a famous political quote, I can see it from my house (at least its mountains). It's a great place, and one of my favorite bookstores is there in Port Angeles, WA. You should check out the superb photography in the NYT story!
OK, it's a human interest story — complete with the required diner! — and shouldn't be taken seriously. Still, it is in the Times and it makes a somewhat explicit statistical claim. So it's fair game to examine whether voters in Clallam County, Washington (in a great diner) are "resembling a prediction."
In this post, I examine the following question: given 11 elections, how many of the 3000 counties would be on the "winning" side in all of them, simply due to random chance?
Is the NYT reporting something interesting? Or are they making a story from random data? Here are some simple ways I answer that.
Approach 1: Mental Arithmetic
For simplicity, let's assume that every election is exactly 50/50. If we make a single guess, we have p=0.5 odds of getting it correct, or 1 chance out of 2 outcomes. With a second election, there are 4 possible outcomes (2^2), and the random odds of getting both correct are 1 out of 4.
In 11 elections there are 2^11 outcomes. If you know the powers of 2, as many programmers do, that's 2048 outcomes.
Or you might approximate it as follows: 2^8 = 256 and 2^3 = 8, so 2^11 is 256 * 8, or about 250 * 8, which is 2000. Or 250 * 10 less 20%, which is 2500 - 500 = 2000.
From that, we might expect about 1/2000 counties to get 11 elections correct, randomly. An observation of 1/3000 is roughly what we'd expect randomly.
Approach 2: Binomial Confidence Intervals
We can formalize that with a binomial test. Suppose we have 11 independent elections, with 0.5 odds in each one, 3000 counties, and observe 1 success case.
Here's the R code:
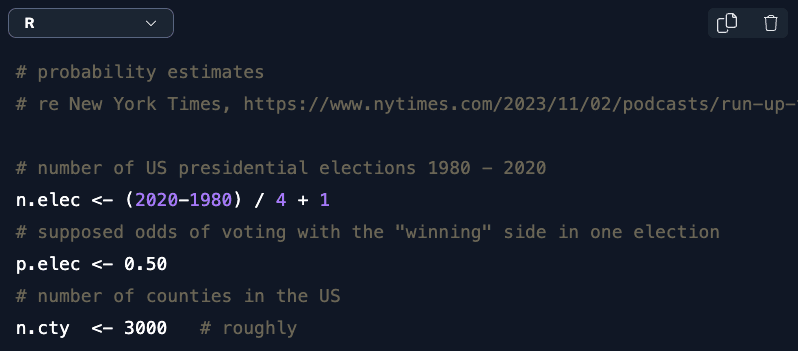
# number of US presidential elections 1980 - 2020
n.elec <- (2020-1980) / 4 + 1
# supposed odds of voting with the "winning" side in one election
p.elec <- 0.50
# number of counties in the US
n.cty <- 3000 # roughly
# odds of observing 1 success in 3000 counties, assuming 11 elections at 0.5 odds
binom.test(x=1, n=n.cty, p = p.elec ^ n.elec)
The result is:

To expand on that, let's multiply the confidence intervals by the sample size to get the expected number of successes rather than the proportion:
# confidence intervals around that observation
binom.test(x=1, n=n.cty, p = p.elec ^ n.elec)$conf.int * n.cty # (0-6 expected "successes")
That is:

Under our assumptions, we expect 0 - 6 counties to get it right. So observing 1 county is not interesting statistically. (It's still a well-photographed story!)
R has other binomial estimation methods that are robust to extremely small proportions, in the binom package. Here's the code and result:
# estimates using multiple methods
library(binom) # install if needed
binom.confint(x=1, n=n.cty)
# see the confidence intervals (0-7 successes expected)
binom.confint(x=1, n=n.cty)[ , c("lower", "upper")] * n.cty

Using every binomial estimation method, we expect somewhere between 0 and 3-7 counties to get it right (again, under the assumptions we made).
Approach 3: Binomial Distribution
Another binomial approach is to examine the density — i.e., the likelihood — of particular outcomes. In R, dbinom() is the density function for the exact binomial test.
What's the most likely observation for the number of counties? Let's plot the likelihood of observing 0:10 successes (i.e., counties) that correctly call all 11 elections in a row under our assumptions. First the R code:
# plot of the density function shows the most likely number of successes
plot(x=0:10, y=dbinom(0:10, n.cty, p = p.elec ^ n.elec),
main="Expected using coin flip odds", xlab="Number of counties, assuming independent random events")
Here's the plot:

If the county results are random and independent, the single most likely result is that exactly 1 county would align with 11 elections. Maybe 0 or 2, or 3, or 4. Almost certainly fewer than 8.
Although I love Clallam County, WA, and enjoy reading about the people there, the result highlighted in the New York Times appears to be random.
But It's Not Random
If you follow elections closely, you'll be aware of the limitations of such simple analyses. Each variable in my simple binomial assumptions is imprecise:
The odds of aligning with the outcome are not 50/50. When there is a landslide election (like Reagan in 1984) more counties will have a higher likelihood of aligning with the vote.
Votes are not equally distributed across counties. Most counties have small populations, and it's possible to win in a relative landslide while winning few counties (In 2012, Obama won 51% of the vote and 62% of the electoral college, but only 22% of counties.)
Side question: are there articles about counties that are wrong in every election? Statistically, that would be just as interesting!Counties are not predictors of, or otherwise related to, national elections. Instead, for national elections, counties are just a way to aggregate and report votes. The nests are
Electoral College <== States <== Voters, and separatelyCounties <== Voters. (Although counties are nested inside states geographically, they are not meaningful units in an electoral sense.)Results from one election to the next — the 11 wins in a row — are not independent probabilities. Many counties never vary, always voting the same way in presidential elections.
Counties are correlated and not independent of one another, so there are not 3000 independent actors.
One might model each of those things under various assumptions (hello, FiveThirtyEight). Overall I would expect that such modeling to have modest effects — highly significant in terms of predicting elections but unlikely to have a vastly different answer to the question we examined.
However, the primary point of this post remains: simple stats and mental arithmetic suggest that although the New York Times story might be fun, it is not serious. They should know better.
But did I mention that the photos are excellent? I recommend visiting Clallam County!
All the Code
Here's the complete R code — plus a brief, bonus snippet for the Electoral College vote shares. (For more on binomial models, see Chapter 4 in the R book or Python book.)
# probability estimates
# re New York Times, https://www.nytimes.com/2023/11/02/podcasts/run-up-trump-biden-election.html
# number of US presidential elections 1980 - 2020
n.elec <- (2020-1980) / 4 + 1
# supposed odds of voting with the "winning" side in one election
p.elec <- 0.50
# number of counties in the US
n.cty <- 3000 # roughly
# odds of observing 1 success in 3000 counties, assuming 11 elections at 0.5 odds
binom.test(x=1, n=n.cty, p = p.elec ^ n.elec)
# confidence intervals around that observation
binom.test(x=1, n=n.cty, p = p.elec ^ n.elec)$conf.int * n.cty # (0-6 expected "successes")
# estimates using multiple methods
library(binom) # install if needed
binom.confint(x=1, n=n.cty)
# see the confidence intervals (0-7 successes expected)
binom.confint(x=1, n=n.cty)[ , c("lower", "upper")] * n.cty
# plot of the density function shows the most likely number of successes
plot(x=0:10, y=dbinom(0:10, n.cty, p = p.elec ^ n.elec),
main="Expected using coin flip odds", xlab="Number of counties, assuming independent random events")
# history of electoral college proportions
margin.elec <- c(0.909, 0.976, 0.792, 0.688, 0.704, 0.504, 0.532, 0.678, 0.617, 0.565, 0.569)
(mean.elec <- exp(mean(log(margin.elec)))) # geometric mean
# expected number of "correct calls", using electoral college probabilities
plot(x=0:60, y=dbinom(0:60, n.cty, p = mean.elec ^ n.elec),
main="Expected using electoral college", xlab="Number of 'wins' out of 3000")