Debunking LLM "IQ Test" Results
C
President, Quant UX Association. Previously: Principal UX Researcher @ Google; Amazon Lab 126; Microsoft. Author of "Quantitative User Experience Research" and "[R | Python] for Marketing Research and Analytics".
Search for a command to run...
No comments yet. Be the first to comment.
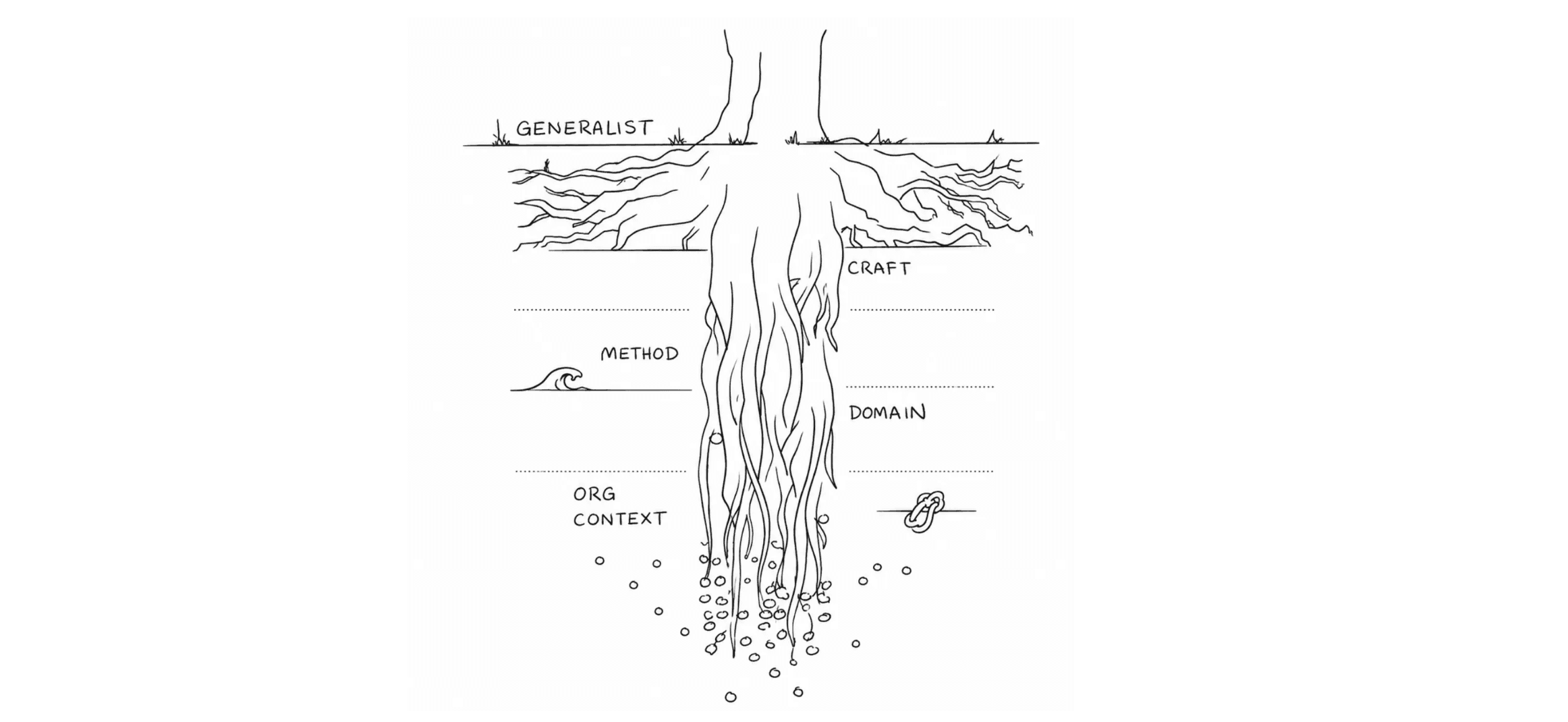
On finding the depth that sets you apart, and earning a reputation along the way
I'm often asked to recommend a tool or vendor for a research project. Over the course of 20+ years doing applied research, I've come to rely on a set of suppliers and software to consider when needed

I’ve recently had discussions with other Quant UXRs about “rigor” and what it means in our work. I’ve often heard it raised as a question over the years, and this prompted me to compile some thoughts. I propose a stack with 4 levels of how I view “ri...

Kelly Moran [Note from Chris: This week I've invited a post from Kelly Moran, a longtime colleague and exceptionally thoughtful and experienced qualitative researcher and anthropologist. Many of us are familiar with the qual/quant "sandwich" that alt...

In the past few months, I’ve had many conversations with senior folks across a variety of MAMANG and similar companies. These are all UXR managers or senior ICs (L5 and up, largely L6-L8 if you’re familiar with those levels). I expected to hear a var...

An article earlier this year in Scientific American claimed that:
the Verbal IQ of the ChatGPT was 155, superior to 99.9 percent of the test takers who make up the American WAIS III standardization sample ... so ChatGPT appears to be very intelligent by any human standards.
-- Eka Roivainen, Scientific American, March 2023
The author is a clinical psychologist with training in cognitive testing ... and I am, too (although I no longer practice). The claim that ChatGPT has a high IQ is nonsense and clickbait at best. At worst, it is intentionally misleading. Here's why.
Summary: IQ test items reflect assumptions — such as working memory and prior item exposure — that do not apply to AI. Generally, "Intelligence" does not mean the same thing for LLMs and humans, and AIs cannot be assessed with human tests. Also, LLMs may be trained on IQ test items. There are tests applicable to both AI and humans, and AI performance is nowhere near human levels of reasoning.
Disclaimer for fellow psychologists. In this post, I give arguments at the first level of detail. Every aspect of "IQ" has been debated in at least thousands of articles and hundreds of books; there's plenty more to say. This post is for a general audience.
WAIS-III? The author used the WAIS-III test, which was replaced by the WAIS-IV in 2008. That is a fishy signal; I say more later in the post.
As for IQ, one might challenge the premise. Some argue that "intelligence" is so broad that it is meaningless and not measurable, is so multidimensional that any assessment is woefully incomplete, and that IQ tests are culturally biased and inappropriate. I'll stipulate that those complaints are plausible and I'm not defending the idea of IQ. However, we don't need to resolve those claims to explain the problems and debunk the application of IQ tests to LLMs. Even if human IQ tests were perfect (or completely imperfect), they would not apply to LLMs.
This section is the longest in this article and establishes the foundation.
Every psychological test is designed to assess a presumed mental state or capacity. An IQ test assesses presumed "intelligence," and a depression inventory assesses "depression," and so forth. The quotation marks are significant. Intelligence, depression, and other psychological capabilities and states are not observable things in themselves. They must be intentionally defined as "intelligence," "depression," and the like before they can be measured. Such a definition is known as a theoretical construct.
As used in IQ tests, "intelligence" is a hierarchical construct where, for example, general intelligence (the controversial "g") underlies verbal intelligence, logical intelligence, mathematical intelligence, processing speed, and the like. Each of those facets in turn underlies further branches such as verbal intelligence underlying vocabulary, metaphors, reading, and so forth. (Again, I'm not defending that model, just explaining it.)
The elements of an IQ test depend on five things: (1) initially observing differences among people, (2) conceptualizing those differences as a construct, "intelligence", (3) creating items that purport to measure that construct, (4) validating that the items do, in fact, measure the differences as intended, and (5) compiling empirical distributions of results in order to compare people to empirical norms.
To see how those work, I'll sketch an extremely simplified and highly idealized scheme of how an IQ test might be developed:
Researchers start with the concept that there is a human capacity called "intelligence" that differs among people. For various reasons — good or nefarious — they want to assess the purported differences among people.
They consider many different ways that "intelligence" appears in people. That might include the size of one's vocabulary, the ability to understand metaphors, performance in school, making logically correct arguments, solving puzzles, doing math correctly and quickly, writing convincing essays, learning a job, etc.
They narrow those down to areas that are reasonably assessable on a test, such as vocabulary questions, math problems, and logic puzzles.
They write many items and examine how well they work — both in agreement with one another and with other tests, and in differentiation from tests of other concepts. (See my post on convergent and discriminant validity.)
After many rounds — and this has been going on for decades — they select "validated" sets of items that are expected to capture differences among people.
The final test is given to thousands of people, so any person's total score may be compared to the population at large.
What you should notice in all of that is the following: the construct of intelligence, its implementation in specific items, and the final empirical norming all relate to observations and theories of humans only. The construct, items, and norms in this general process do not relate to LLMs, to differences among LLMs, or to comparisons between LLMs and humans.
Let's dig into that a bit further to see why it is important. Suppose one believes — as many IQ test authors have believed — that the size of one's vocabulary is an indicator of intelligence. Vocabulary size is easily amenable to testing: one can write test items that assess knowledge of frequently and infrequently used words.
Yet such an item relies on human-centric standards of what it means for a word to be "infrequently" used and how that relates to "knowledge" of vocabulary. In other words, it makes assumptions about language exposure and memory that only apply to humans. LLMs do not have human language exposure — they are trained on billions of documents — and they do not have human memory.
Thus, LLMs cannot be expected to show the same putative linkage between vocabulary and "intelligence" that humans show. Vocabulary size could be a reasonable indicator of "intelligence" for humans and yet a terrible indicator of intelligence for non-human entities. One would not claim that a dictionary has a "verbal IQ" ... and neither should one claim it for an LLM.
To summarize, IQ test items presuppose human capacities and performance. They do not apply to other entities — dogs, dolphins, dictionaries, or LLMs. Other entities should be assessed either on their own, according to a relevant construct of "intelligence" ... or assessed using a construct that is developed from the beginning to apply across entities and not merely to humans (we'll see an example below).
It might help to show a couple of verbal IQ item examples. These are not from the WAIS (its items cannot be published) but are from an online IQ testing site, "IQ Test Experts" (I'm noting it; not recommending it). Here are two items:
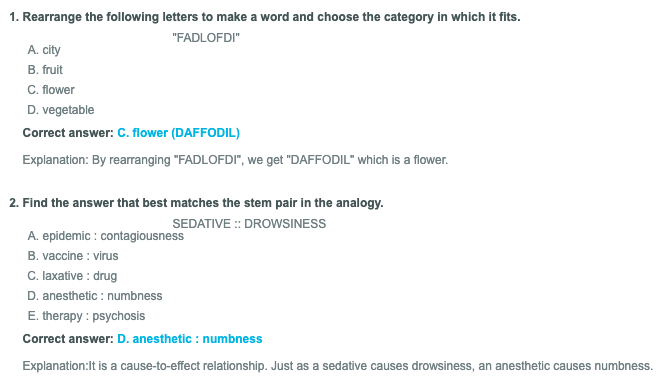
When we consider how an LLM might answer these items — using statistical correlations from text documents — it is fairly obvious how they can be "solved" by training, rather than reasoning as such.
Item 1 can be "solved" by finding the maximum statistical correlation in two conditions: the correlations between a set of letters and the words in a dictionary; and then the correlation between one word (daffodil) and another word (flower). That is exactly what LLMs are designed to do. For an LLM, such an item does not have the same relationship to "intelligence" as it does for humans.
Item 2 is similar. An LLM has measured the relative frequency of words co-occurring in text. I would strongly expect that "sedative, drowsiness" occur more often in contexts with "anesthetic, numbness" than the other pairs of words. No understanding of a cause-and-effect relationship is needed, given a training corpus.
This point follows from the previous section: items on an IQ test are indicators of intelligence and do not, in themselves, form a definition of intelligence.
(As an aside, there is a skeptical tradition in psychology that holds that "intelligence" means nothing more than "what an IQ test measures." That is amusing and makes a point, but is not a serious definition due to its circularity. I'll set that aside.)
The fact that items are indicators and not definitions can be demonstrated in two ways. First, one may look at the history of how IQ tests are developed, as noted above, and how items are explicitly selected to be indicators of underlying constructs, based on observations of people. Second, one might apply a reductio ad absurdum analysis: if correct answers alone were a manifestation of intelligence, then (for example) a hole-punching press would be perfectly intelligent when taking a test administered on punch cards after it is "trained".
As noted above, the connection between item responses and the concept of "intelligence" depends on the context of being assessed among people. It does not apply to LLMs.
Here's another example. Consider the construct of "athletic performance." It is generally conceived that some people are more athletic than others, and we might wish to assess that. Among humans, two indicators might be (1) the time to complete a marathon, and (2) the height one can jump. Yet it would be absurd to claim that an airliner is more "athletic" than a human on the basis that it can cover 26 miles in 3 minutes at a height of 39000 feet. Similarly, it is absurd to claim that an LLM is more "intelligent" than a human because it "remembers" tens of thousands of words.
The next point is closely related but I want to make it clear. If one believes that LLMs have intelligence, the proper way to assess it is to define what "intelligence" means for LLMs. Then write, validate, and emprically assess items that measure an LLM-relevant construct.
The wrong way to assess "intelligence" in LLMs is to give LLMs a test that was developed for humans only, and that presumes human memory and exposure to the test items.
Here's an analogous situation: suppose I give an IQ test to my dog (who of course is a very good dog ... and a very smart dog, too, yes he is, here's a treat). Depending on the method of administration, I would expect my dog to answer 0 items correctly on a human IQ test. Does that mean that he is far less "intelligent" than humans?
"Intelligent" in what way? An average dog's intelligence is neither "more" nor "less" than the intelligence of an average human because human intelligence and dog intelligence are not comparable on a dimensional scale. They are different.
How might we assess LLMs? To see how LLMs might be tested for higher-order capabilities, check out the discussion by Melanie Mitchell of the "abstraction and reasoning corpus" for AI models. Mitchell shows how LLMs fail at many rudimentary tasks of abstraction.
We'll see more in the next section ... or check out AI engineer Francois Chollet's paper, "On the Measure of Intelligence".
The Scientific American article claimed that:
ChatGPT appears to be very intelligent by any human standards
"Any human standards"? That is manifestly untrue. Chollet and Mitchell show (for example) how tests of abstraction that are simple for humans are routinely failed by various AI systems and LLMs.
At this time of writing, there is a competition of intelligence problems for AI models, the "ARC [abstraction and reasoning corpus] Challenge." The sponsors note that:
Although humans typically achieve an 80% success rate in solving ARC tasks, existing algorithms have only managed to reach 30.5%, which stands as the current world record achieved through the combination of various algorithms specifically designed for ARC. (link)
Thus, ChatGPT is not yet "very intelligent" compared to this human standard. To the extent that an AI performs even at the 30% level on this test — compared to the average human 80% level — it requires an AI with a specialized design explicitly intended not to be a general AI but to solve these kinds of problems.
Here's an example of an ARC problem (from https://lab42.global/arc/):
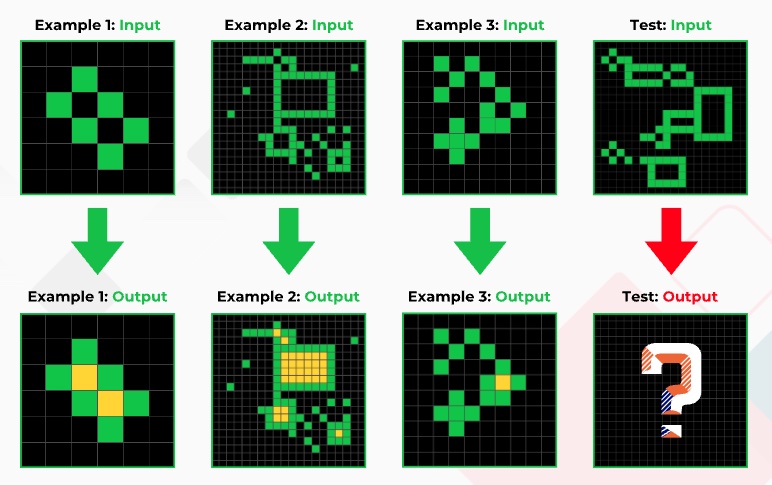
Take a moment and think about the answer to the test case. For humans, the solution is straightforward.
But that problem is not easy for LLMs, unless they have seen the answer in their training set. Why not? Because it relies upon abstractions that are easy for humans (surrounded area => fill in, same color) but that are foreign to computers. One might design a "surrounded area filling in" algorithm ... but the point is that there is a vast array of similar abstractions that come naturally to humans but not AI. (More here.)
This demonstrates again how intelligence is different for AI vs. humans. Humans who perform well on one test (such as the WAIS-III IQ test) also tend to perform well on a different test (such as the ARC). Setting aside the controversies, one might argue that the tests measure the same thing ("intelligence") in different but related ways, among people. However, an LLM may perform well on the WAIS but terribly on the ARC, because the tests do not measure related things, among LLMs.
Intelligence does not generalize for LLMs in the way it does for humans. LLMs may perform well on some problems, where they have detailed algorithmic design or training, while they perform quite poorly on other tests. (For more on AGI and how human intelligence is far broader than LLM capabilities, see this post.)
This is perhaps the biggest issue of all: for standard IQ tests like the WAIS, an LLM has most likely seen the questions and memorized the answers. Put differently, the administration is violating standard test-taking conditions. In effect, it is like giving someone an open-book test with unlimited time to find answers.
I don't have a WAIS-III manual on hand, but I do have a WISC-III manual from my clinical days (that's the parallel test except for children). The testing manual — like all professional IQ testing manuals that I've seen — has statements like the following, which warn of the invalidity of the test when standard conditions are violated:
[The] examiner should be aware of practice effects — increases in test scores as a function of prior exposure to the test. ... [The] examiner should allow as much time as possible between the testings and, if a short retest interval is necessary, should interpret the results cautiously. [pp. 7-8]
[The] WISC-III was developed for use with children ... [p. 8]
The purpose of the WISC-III is to assess a child's performance under a fixed set of conditions. In order to obtain results that are interpretable according to traditional norms, you should adhere carefully to the administration and scoring directions [p. 33]
When testing LLMs, so many conditions differ — typing items instead of reading them, the lack of physical observation, the exclusion of tests that require physical interaction, and of course violation of prior exposure times and memory assumptions — that it is unreasonable to assume that the test-taking conditions are appropriate. The IQ test manual itself says that the results are invalid.
Similarly, a typical license condition for psychologists who use such tests is that they will keep the items confidential and not release them publicly. That is both for intellectual property reasons and to reduce people's ability to prepare for the test and cheat on the norms. Using such items with ChatGPT might violate the license ... and may train the LLM on them! Perhaps that is why the Scientific American author used the WAIS-III instead of the current WAIS-IV — but even if so, the copyright and license conditions of previous versions are not canceled by a new version, and items remain similar or sometimes identical across versions.
In summary, to assess "intelligence" in AI models, one must use specially designed tests like the ARC battery mentioned above. Some of those (like ARC) can be administered to people as well as AI systems, and use hold-out items that cannot be trained in advance. One should not compare AI "intelligence" to humans unless such an appropriate test, developed and normed for both AI and humans, is being used.
When you see claims about AI "intelligence," ask yourself:
Could the AI have seen and memorized the answers? (For standard human cognitive tests, the answer is yes.)
Has the test been developed specifically for an AI-appropriate definition of "intelligence"? (The general answer is no.)
Has it been normed in some way that would permit comparison to human intelligence? (Again, probably not.)
What aspects of intelligence are missing? Is the author making expansive claims based on a limited, narrow test such as vocabulary?
Finally ... I'm disappointed that Scientific American would publish the article referenced. Yet the publication in itself is a good reminder of the so-called Gell-Mann Amnesia Effect (named after the Nobel Prize-winning physicist, Murray Gell-Mann):
Briefly stated, the Gell-Mann Amnesia effect works as follows. You open the newspaper to an article on some subject you know well. ... You read the article and see the journalist has absolutely no understanding of either the facts or the issues. Often, the article is so wrong it actually presents the story backward —reversing cause and effect.
I call these the "wet streets cause rain" stories. Paper's full of them.
In any case, you read with exasperation or amusement the multiple errors in a story — and then turn the page to national or international affairs, and read with renewed interest as if the rest of the newspaper was somehow more accurate about far-off Palestine [for example] than it was about the story you just read. You turn the page and forget what you know.
-- Michael Crichton, 2002 (reference)
Now you know more about IQ tests and AI than the editors and the author in Scientific American. Thanks for reading!
P.S. If you're interested, in a different post I outline many ways in which human cognition differs from LLMs and yet are rarely mentioned in AGI discussions.
