Favorite R packages, Part 2
A walkthrough of the code that counts my favorite packages
In Part 1, I listed the R packages that I use most often in my code. In this post, I walk through the R code that found that list. I discuss each chunk of that code and compile the entire code file at the end.
Along the way, I demonstrate how to clarify the assumptions and outline the code before writing it, similar to a whiteboard coding interview. I also leave in all of my heavily commented notes. Those comments demonstrate how I explain code to myself and make it more readable by future-me. (FWIW, this structure of "show, explain, share" for code files is similar to many chapters of the R book and Quant book.)
If you're not interested in R coding, or if the problem outlined in the "Goal" section seems simple, this is not a post for you!
Goal
For any coding task, we need a clear goal and set of assumptions. The goals for the current code are:
Find the total list of unique R packages that I use in my R code
Count the occurrence of each package (how many files invoke it)
Report and also plot those frequencies
In any coding exercise (or interview) we must clarify the boundaries of the problem. Some questions will arise only after you begin coding, but two obvious initial questions are:
Q: What is an R code file to be counted? Assumption: it is any file nested under my personal folder structure, whose name ends with "
.R"Q: What does it mean to "use a package"? Assumption: it is any line of code appearing in a file that contains the string "
library(PKG)" or "require(PKG)" where "PKG" is the name of some package.Q: Do we care about package dependencies or whether we accidentally count an apparent call in a commented line? Assumption: no.
Q: How about packages that are called multiple times within a single file? Do we count every line? Assumption: no, we count only once per file.
These assumptions will appear clearly in the code below.
Whiteboard version
For almost any coding task, I start with a "whiteboard" version that outlines the overall steps (the algorithm, as it were). For this problem, an outline is:
initialize COUNTS[packages] to NULL
get the FILENAMES for all the R files we will process
for each file FILE in FILENAMES
.. read all lines of FILE
.. for each LINE in FILE
.. .. if LINE contains "library(*" or "require(*"
.. .. .. PKG <- extract the string "*" from library(*) or require(*)
.. .. .. if PKG %in% COUNTS
.. .. .. .. COUNTS(PKG) <- COUNTS(PKG) + 1
.. .. .. else
.. .. .. .. COUNTS(PKG) <- 1
.. .. .. end if PKG %in% COUNTS
.. .. end if LINE contains library or require
.. end for LINE
end for FILE
plot COUNTS
Notice that I use ".." to mimic code indention when I write free text outlines like the above. That makes the logic easier to follow. I write "end" clauses descriptively rather than using brackets ({ and }) because it is more readable. (It is also similar to Pascal and other old-school programming languages. In fact, I often retain them using in my code, such as "} # end for" although I don't do that here.)
What do I do with this outline? I usually put the outline directly into RStudio and then start writing code that gradually replaces each line.
Your style may vary, but with something that approximates the outline above, you will have a great running start for your code. Also — I'll say it again — this is a good structure when answering programming interview questions. The interviewer (hopefully) will be more interested in your logic and the ability to use control structures than in detailed syntax. In an interview, I would make the outline closer to real R code (or Python, etc) than is shown here, but the overall algorithmic structure would be the same.
Step 1: Get the Vector of Files to Process
Now let's see the real code. In the first chunk, we set up some preliminary requirements and implement assumption #1 above about which files to count.
library(gsubfn) # fast string extraction in case of large files
# recursively traverse and get names of files to parse
# assumes all files live below a certain root, and end with .R | .r
# first, set where your files are
######## vvvvvvvvvvvvv
filepath <- "~/Documents/R" #### <<== CHANGE THIS AS NEEDED
# then get the names of all the R files there
all.files <- list.files(filepath, recursive=TRUE)
R.files <- all.files[grepl(".R$", all.files, ignore.case = TRUE)]
This should be self-explanatory except for the last two lines. The first of those gets ALL of the filenames located underneath (recursive=TRUE) the specified folder path. The second line uses a regex (regular expression) to get only the filenames that end ($) with ".R" (or ".r", because ignore.case=TRUE).
That gives us the list of R code files that we will examine, R.files.
Step 2: Set up the Counting
We set up a hash table (technically, an R environment) to hold our counts using new.env(). I describe how that works in a post about hash tables in R. One might use a data frame or list instead, but a hash table is optimal.
Then we iterate over all of the file names, R.files using a for() loop. In R, as long as a vector has one or more elements, you can iterate directly on them with no need to have an index counter. (Safer would be to use seq_along() as we describe in the R book.) Intermediate note: a more advanced would be to write a function to process one file, then iterate with an apply() variant. However, a for() is simpler and it's good (especially in interviews) to keep things simple.
# initialize a hash table to use for counting
package.counts <- new.env()
# process each file
for (filename in R.files) {
# [processing code omitted -- we'll see this part below]
}
Step 3: Get the List of Packages from a File
Given filename, we read the file and then process all of its lines at once. Note that this code diverges in apparent structure from the "whiteboard" version above. In the outline, I wrote an inner, second for() loop that processes every individual line from filename. However, in the real version, I use vectorized code and a variant of *apply() to handle all of the lines simultaneously.
This *apply() approach is more efficient and, to a fluent R coder, is more readable. However, if you're just learning R, a nested for() loop is an acceptable alternative. (We say more about vectorized code in the R book and, relative to for() loops, in the Quant book.)
Here's the code chunk. I'll point out some aspects of it below.
# read the lines from each file (combining path + filename as found above)
# we use warn=FALSE because .R files are OK if they end without the traditional EOF
fileLines <- readLines(con=file(paste0(filepath, "/", filename)), warn = FALSE)
# in the file we just read, find lines with "library(*)" or "require(*)"
# and extract the "*" part from those lines, between the parentheses
set1 <- unlist(strapplyc(fileLines, "library\\((.*)\\)", simplify = TRUE))
set2 <- unlist(strapplyc(fileLines, "require\\((.*)\\)", simplify = TRUE))
# combine the "library" and "require" sets and clean them up
packageSet <- unique(c(set1, set2))
# clean up any extraneous quotation marks (we'll add consistent ones in a moment)
packageSet <- gsub('"', '', packageSet) # packages can be used w/ or w/o quotation marks
packageSet <- gsub(')', '', packageSet) # "if(require())" can leave extra parenthesis
# now add consistent quotation marks to all, so package names are not interpreted
# by R as the package objects themselves, but as strings
packageSet <- paste0('"', packageSet, '"')
The two most important commands are lines 7 and 8 in this chunk, which use a regex to get the lines that contain "library(*)" or "require(*)" and extract the "*" part. Here's how those work:
We will
*apply()to every line a string matching function (strapplyc()from thegsubfnstring processing package).That uses a regex to find "
library()" or "require()". Parentheses have a special function in a regex of grouping a portion that you wish to extract — in this case the ".*" part, which is thus written as "(.*)". That says, give me the part that ".*"matches.However, we also want to find parenthesis characters that are part of the search string itself, and have to tell R when those are to be interpreted as characters and not as part of the regex; that's done with the double escape "
\\(" and "\\)" syntax. That gives us "library\\((.*)\\)" and "require\\((.*)\\)"We apply that regex to every line using
strapplyc(), usingsimplifyto give a vector for each line instead of a list.Then, we
unlist()the results into a single vector. This vector will have all of the extracted package names for the whole file.
Remember that we want to count a package only once per file. We combine the packages found for "library" and "require", and then keep only the ones that are unique (not called multiple times in the file). That line is packageSet <- unique(c(set1, set2)) .
Finally, for reasons noted in the comments, I add quotation marks to all package names (thus ggplot2 is counted as 'ggplot2') and do some other cleanup. Such details are nearly impossible to anticipate; you have to run and debug the code to discover them!
Step 4: Show Progress
I hate having code run without knowing what it's doing. So I show each file as it is being processed, and what was found.
# show our progress
cat("file:", filename, "\n")
cat("packages:", packageSet, "\n")
Step 5: Add the Packages in filename to our Counts
This part is pretty simple, as explained in the post about hash tables. For each package, we increment its count in the hash table package.counts.
I was lazy here and used i in the for() loop. An iterator name like "package" would be better — but at some point, things are obvious, and i is OK in a short chunk.
# add the the packages to our counting hash table
for (i in packageSet) {
# if we haven't seen package i before, set its initial appearance
if (!exists(i, package.counts)) {
package.counts[[i]] <- 1
} else {
# otherwise, increment how many times we've seen it
package.counts[[i]] <- package.counts[[i]] + 1
}
# show more progress
cat(i, " == ", package.counts[[i]], "\n")
}
cat("\n")
Step 6: Put the Package Counts into a Useful Form
In this chunk, we first examine what we found and then put the package names and counts into a data frame.
The most important but cryptic code is this: data.frame(unlist(mget(names(package.counts), envir=package.counts))). Let's unpack that.
The inner part,
names(package.counts)gets all of the package names from our counting object (i.e., the keys of the hash table).Then it uses
mget()to get the matching values from the hash table for each of those keys (specfically, in the environmentenvir=package.counts).As above, it uses
unlist()to turn those counts into a vector.Then it creates a
data.frame()for those counts.
After that, I put the names into a dedicated column in the data frame. I use gsub() to remove the quotation marks added to each package name, and rename the counts column to "freq".
# which packages were used?
names(package.counts)
# and how many times?
ls.str(package.counts)
# put the counts into a data frame
packages.dat <- data.frame(unlist(mget(names(package.counts), envir=package.counts)))
# set a "names" column for the packages, and remove the quotation marks at this point
packages.dat$name <- gsub('"', '', rownames(packages.dat))
# rename the counts column
names(packages.dat)[1] <- "freq"
Step 7: Clean up and Check the Data Frame
When inspecting the data frame, I find a few entries that are junk for various reasons (e.g., they are comments about the require() function or example code with fake package names). Also there is one entry ("") that counts all of the files that had zero packages invoked and I'm not interested to plot that count.
Always expect some degree of hand tuning for any data set! I remove 5 lines from the data frame for those reasons.
Then I do a bit more cleanup for reasons as noted in the comments, and we're ready to plot the results.
# remove a few entries that reflect random things like the regex in this script
######## vvvvvvvvvvvvvvvvvvvvv
packages.dat.clean <- packages.dat[-c(17, 29, 64, 78, 82), ] #### <<== CHANGE THIS AS NEEDED
# make sure we didn't see any unintended duplications due to odd names etc.
packages.dat.clean$name[duplicated(packages.dat.clean$name)]
# put package names in reversed order (b/c ggplot2 annoyingly reverses them IMO)
packages.dat.clean$name <- factor(packages.dat.clean$name,
levels=rev(sort(packages.dat.clean$name)))
packages.dat.clean
Step 8: Plot the Results
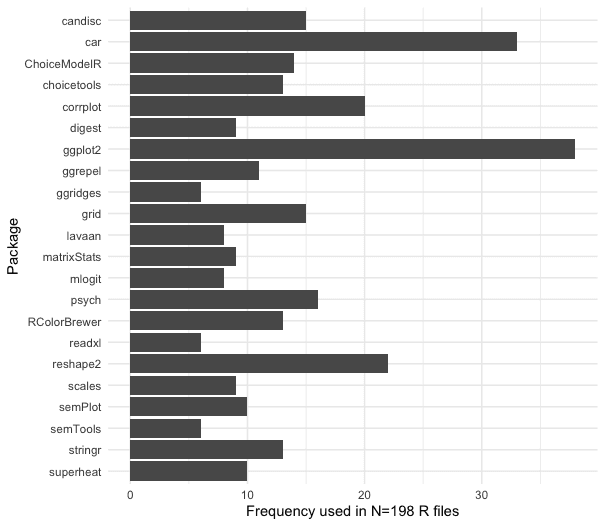
This code should be straightforward. Basically, I plot the frequency counts vs. the package names, but use subset(.., freq > 5) to make the plot simpler by eliminating packages that appeared fewer than six times.
This code uses geom_text() to add the counts as labels on each bar, and rotates the chart 90 degrees to be more readable with coord_flip(). The result is shown below:
# plot the result
library(ggplot2)
p <- ggplot(aes(x=name, y=freq),
data=subset(packages.dat.clean, freq > 5)) +
geom_col() +
geom_text(aes(label=freq), size=3, hjust=-0.2) +
coord_flip() +
xlab("Package") +
ylab(paste0("Frequency used in N=", length(R.files), " R files")) +
theme_minimal()
p
Following is the actual chart (see Part 1 for its interpretation):

Whew! It is always interesting how a simple goal turns into more code than one expects.
Side note about interviews: in a programming interview, you would certainly not accomplish anything like this much code or output. Don't worry about that! A reasonable expectation in an hour-long interview would be to note the goals and assumptions (as described above) plus something like my "whiteboard" outline of the code.
Still, it is highly useful to put yourself through real coding exercises for these kinds of problems. Writing such code improves your skill at probing an interviewer's goals, making reasonable assumptions, and writing intial whiteboard code.
Further Improvements
In a programming interview — or if you needed to put such a project into production rather than a one-off analysis — you could expect questions such as the following. (I won't give the answers, because they are good thought exercises if you're learning to code.)
What are edge cases where your code fails?
How would you write a function to process one file?
How would you then write a function to process all the files?
At what point would your code break down for performance reasons?
What if you had 100 billion files to process? How would you scale up to handle that?
The answers to such questions depend on your experience, and there is not necessarily any single right answer. We discuss these issues more in Chapter 6 of the Quant book.
One more:
- Why do you sometimes use camel case (e.g.,
packageSet) and sometimes dotted names (e.g.,R.files)? A: OK, I'll answer that one! There is no particularly good answer, I'm just erratic :) Ideally, one would be more consistent (e.g., camel case for function names, dotted for objects; or always camel case; etc.). I've been doing this for so long that I have evolved a somewhat mixed-up style over the years. I'm not a software engineer and I don't worry much about details like that.
For my part, if I needed to run this process more than once or twice, I would break the code into two functions as noted in questions 2 and 3 above. (It would also be great to start with a functional approach instead of the linear, script-like approach I took. But I wanted to share my real code as an example!)
Complete Code
If you'd like to run this on your system, the following is the complete code file. Be sure to read the comments and update two lines as noted.
# count libraries used in a set of R code files (didactic code, not optimal)
# Chris Chapman, 2023, quantuxblog.com
# adjust lines 12 and 75 as needed for your situation
library(gsubfn) # fast string extraction in case of large files
# recursively traverse and get names of files to parse
# assumes all files live below a certain root, and end with .R | .r
# first, set where your files are
######## vvvvvvvvvvvvv
filepath <- "~/Documents/R" #### <<== CHANGE THIS AS NEEDED
# then get the names of all the R files there
all.files <- list.files(filepath, recursive=TRUE)
R.files <- all.files[grepl(".R$", all.files, ignore.case = TRUE)]
# initialize a hash table to use for counting
package.counts <- new.env()
# process each file
for (filename in R.files) {
# read the lines from each file (combining path + filename as found above)
# we use warn=FALSE because .R files are OK if they end without the traditional EOF
fileLines <- readLines(con=file(paste0(filepath, "/", filename)), warn = FALSE)
# in the file we just read, find lines with "library(*)" or "require(*)"
# and extract the "*" part from those lines, between the parentheses
set1 <- unlist(strapplyc(fileLines, "library\\((.*)\\)", simplify = TRUE))
set2 <- unlist(strapplyc(fileLines, "require\\((.*)\\)", simplify = TRUE))
# combine the "library" and "require" sets and clean them up
packageSet <- unique(c(set1, set2))
# clean up any extraneous quotation marks (we'll add consistent ones in a moment)
packageSet <- gsub('"', '', packageSet) # packages can be used w/ or w/o quotation marks
packageSet <- gsub(')', '', packageSet) # "if(require())" can leave extra parenthesis
# now add consistent quotation marks to all, so package names are not interpreted
# by R as the package objects themselves, but as strings
packageSet <- paste0('"', packageSet, '"')
# show our progress
cat("file:", filename, "\n")
cat("packages:", packageSet, "\n")
# add the the packages to our counting hash table
for (i in packageSet) {
# if we haven't seen package i before, set its initial appearance
if (!exists(i, package.counts)) {
package.counts[[i]] <- 1
} else {
# otherwise, increment how many times we've seen it
package.counts[[i]] <- package.counts[[i]] + 1
}
# show more progress
cat(i, " == ", package.counts[[i]], "\n")
}
cat("\n")
}
# which packages were used?
names(package.counts)
# and how many times?
ls.str(package.counts)
# put the counts into a data frame
packages.dat <- data.frame(unlist(mget(names(package.counts), envir=package.counts)))
# set a "names" column for the packages, and remove the quotation marks at this point
packages.dat$name <- gsub('"', '', rownames(packages.dat))
# rename the counts column
names(packages.dat)[1] <- "freq"
# remove a few entries that reflect random things like the regex in this script
######## vvvvvvvvvvvvvvvvvvvvv
packages.dat.clean <- packages.dat[-c(17, 29, 64, 78, 82), ] #### <<== CHANGE THIS AS NEEDED
# make sure we didn't see any unintended duplications due to odd names etc.
packages.dat.clean$name[duplicated(packages.dat.clean$name)]
# put package names in reversed order (b/c ggplot2 annoyingly reverses them IMO)
packages.dat.clean$name <- factor(packages.dat.clean$name,
levels=rev(sort(packages.dat.clean$name)))
packages.dat.clean
# plot the result
library(ggplot2)
p <- ggplot(aes(x=name, y=freq),
data=subset(packages.dat.clean, freq > 5)) +
geom_col() +
geom_text(aes(label=freq), size=3, hjust=-0.2) +
coord_flip() +
xlab("Package") +
ylab(paste0("Frequency used in N=", length(R.files), " R files")) +
theme_minimal()
p