There's a gap between the Quant UX book and my R for Marketing Research book (although it's filled in the Python for Marketing Research book) ... and that concerns hash tables, also known as associative arrays, lookup tables, and dictionaries.
What's a hash table? It's an array of lookup terms that are each associated with some value. These are often expressed as [key, value] pairs, such as [name, phone number] or [jersey number, times at bat] or [license plate, automobile model]. If you're thinking, "that's like a lookup or a key index or a JOIN BY in SQL" then you're exactly right.
The gap is this: in the Quant UX Book we describe understanding hash tables as a basic conceptual skill for quant UX programming ... and yet hash tables are not covered in the R book! There are reasons — e.g., hashes are somewhat indirectly part of the R language, and they are rarely needed by most analysts — and yet they are an important concept to understand and use when needed. (They appear in the Python book as dictionaries, which are a core part of Python.)
Let's fill that gap for the R book! (This also sets the stage for a separate blog post where I count the packages that I most often use in R code.)
Here's the interview question. When I interviewed at Google in 2011, one of the whiteboard programming questions I was given involved counting unique words in a text file. I won't give the full problem, as someone might still use a variation but one part of the discussion went as follows (from my memory):
Google Q: We need to count the frequency of each word. How would you do that?
My A: We could use a hash table with a key, value pair, like [word, count of appearances]. As we read the file, we increment a value each time a given word appears.
Google Q: How would you do that in R? Add this to your code on the whiteboard.
My A: Hmm, I don't recall the exact syntax and I'd look that up. For now, let's assume we have a hash array variable called "hashTable" and that the hash operator is "#". We could use "hashTable#key <- value" where "key" is any of the words.
As an aside, this demonstrates a good practice in whiteboard interviews for quant UX, which is to state assumptions as needed and move along. It was OK for me to use the admittedly incorrect "#" syntax. Quant UX interviews should concern basic fluency and conceptual correctness, not advanced or granular details of syntax (unlike, say, an interview for an operating system software engineer). BTW, full disclosure: in addition to being hired after that set of interviews, from 2017-2022 I led the cross-company team who wrote these kinds of suggested interview questions for quant UXR hiring. Conceptual knowledge is more important than syntax.
[Added: I should clarify that this post is not about the minimal solution to the interview question. The minimal solution is table(words) ... but that will get rejected during a programming interview. The interviewer wants to know whether you can program, and might be expected to follow up with, "Suppose you didn't have table() and had to write it from scratch?" In fact, that's exactly what happened in my interview, and later in many that I gave. The goal of this post is to discuss how hash tables solve the general set of problems like this one, and to see one way to implement them in R.]
So, what is the R syntax for a hash table? Like most things in R, there are multiple solutions and several packages, but the simplest option is available in base R and uses R namespaces ("environments"). In essence, you create a new memory area and put objects into it, which are just like variables in your main working area. Then you access those objects by their names (the "key") and use the names to read or set their values (the "value").
There are 6 key operations we need for an effective hash table:
Create the table
Create an entry with a [key] for a particular [key, value] pair
Assign the [value] to a particular [key, value] pair
Access (read) a value from the table, accessing it with a key
Check the existence of a [key, value] pair
Remove an entry from the table
In R hashes (and almost everywhere else in R), creating an object and assigning its value can be done simultaneously, which means that operations 2 and 3 in this list — create an entry; assign its value — are accomplished identically.
Here is the R syntax and a demonstration for each of those key operations:
- Create the table by using an R environment:
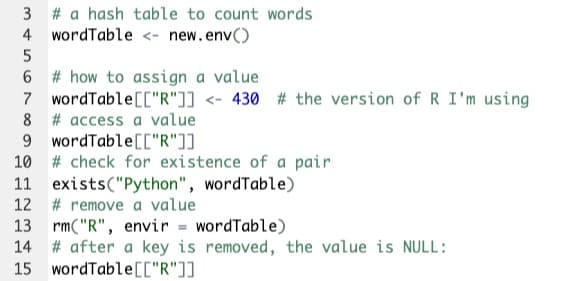
# a hash table to count words
wordTable <- new.env()
Create an entry with a [key] for a particular [key, value] pair
... and also ...Assign the [value] to a particular [key, value] pair
... using the[[ ]]double brackets operator
# how to assign a value
wordTable[["R"]] <- 430 # current R version I'm using BTW
- Access (read) a value from the table, using
[[key]].
Note that the key could be either a literal string as shown here, or a character (string) variable as we'll see below.
# access a value
wordTable[["R"]]
That gives the following result in the R console:
> wordTable[["R"]]
[1] 430
- Check the existence of a [key, value] pair in our hash table, using the key name:
# check for existance of a pair
exists("Python", wordTable)
We don't have an entry named "Python" so the result of that is:
> exists("Python", wordTable)
[1] FALSE
- Remove an entry from the table
# remove a value
rm("R", envir = wordTable)
After removing the "R" pair, its value is NULL:
> rm("R", envir = wordTable)
> wordTable[["R"]]
NULL
We'll see below how to view all of the keys that are available in a hash table.
Now that we've seen the syntax, let's apply R hashes to the interview question, counting the occurrences of words in a set of words. (Note: in a real whiteboard interview, there would be preceding questions about determining what is a word, what language(s), and so forth; we'll assume that is solved. In an interview, clarify those questions and/or state your assumptions.)
First of all, we create a small test set of words to count. In an upcoming post, I'm going to count occurrences of R package usage in my code, so for purposes here, I'll use some package names:
# the set of words to count (package names in this case)
words <- c("'ggplot2'", "'car'", "'ggplot2'", "'lavaan'", "'cluster'", "'viridis'", "'car'", "'ggplot2'")
Although not strictly required in this case, it's generally a good idea to include the extra quotation marks (i.e., "'car'" instead of "car") to ensure that the terms are always treated by R as character strings instead of objects.
Next, we set up a hash table, identical to the code above:
# reset table to start fresh, always good to do immediately before using
wordTable <- new.env()
We then iterate over the words and count them. Here's how. We'll use a for() loop to iterate over the set of words. For each word, we'll check whether it already exists in the table. If it does, then we increment its frequency count by 1. If the word does not exist — if this is the first time, we've seen it — then we add it to the table with an initial value of 1 (its first appearance).
Side discussions before returning to the main topic ...
Iteration in R is a complex topic and I always recommend to start by using a for() loop, especially when doing interviews. It's good to demonstrate awareness of vectorized solutions in R, but I don't recommend or expect candidates to use them as a basic solution. for() loops keep it simple!
Have you heard that you should never use for() loops in R? That is poor advice and is largely obsolete, persisting from the early days of S-Plus (the predecessor language of R). My coauthor Elea Feit and I have more to say about that in the R book. Perhaps I'll do a blog post about that sometime, too.
Side, side note: however, do pay attention when nesting for() loops and be especially concerned when growing data frames inside for() loops. The latter can cause R to make repeated copies of objects and quickly bog down and become super slow (or run out of memory). The R book shows one way to preallocate object space and avoid that problem. For now, I'll set that aside to return to the main topic.
Back to the main topic! Here's the code to iterate and count the words in our set, using the defined hash table:
# iterate over the words and build the hash table
for (i in words) {
if (exists(i, wordTable)) {
wordTable[[i]] <- wordTable[[i]] + 1
} else {
wordTable[[i]] <- 1
}
}
Isn't that simple? The trickiest thing about the syntax is that hash tables use double brackets ("[[ ]]") to access values instead of single brackets ("[ ]"). TBH, I always get that wrong on the first try.
To see the complete set of keys, one approach is to use the names() function:
> names(wordTable) # the keys
[1] "'lavaan'" "'car'" "'ggplot2'" "'viridis'" "'cluster'"
There is a hash table variation of the str() command to inspect an object's structure, ls.str() (which is to list objects via ls() — in this case, the objects in our named environment that is the hash object — and get the structure str() of each one). That is:
> ls.str(wordTable) # the structure, i.e., key and value of each object
'car': num 2
'cluster' : num 1
'ggplot2' : num 3
'lavaan' : num 1
'viridis' : num 1
Programmatically, we might use a for() loop again to access all of the keys and their values:
# iterate over all the keys and print the values
for (i in names(wordTable)) {
cat(i, wordTable[[i]], "\n")
}
The result — the list of packages and the counts of how many times each appeared in our set — is:
'lavaan' 1
'car' 2
'ggplot2' 3
'viridis' 1
'cluster' 1
That's it! If you use R and need hash tables — or get an interview question about them — this is what you'll need to know, at least to get started.
For higher performance and additional options, there are solutions such as the hash package or using a data table. In the Quant UX book, we discuss some likely follow-up questions to any interview topic like this, such as how to increase the scale and performance for large data sets.
A key conceptual point about hash tables is that they have very high performance for making [key, value] pairs and looking up the [values] later. Other data structures have lower performance when, for example, they rely on iteratively searching through the [keys] to find a match. However, I'm not going to get into the mechanics of how hash tables accomplish their high performance (although it's interesting and simple, that is also easy to find in general CS sources; I want to fill the gap that is specific to R and my two books).
If you're really interested, you can learn more about the internal workings of R environments and how those relate to hash tables in Chapter 7 of Wickham's Advanced R book (this is not needed for most Quant UXRs!)
Finally, to make it easy for you to copy and paste, here's all the code from this article in one chunk:
# hash table demo for Quant UX Blog
# a hash table to count words
wordTable <- new.env()
# how to assign a value
wordTable[["R"]] <- 430 # the version of R I'm using
# access a value
wordTable[["R"]]
# check for existance of a pair
exists("Python", wordTable)
# remove a value
rm("R", envir = wordTable)
# after a key is removed, the value is NULL:
wordTable[["R"]]
# view the keys
names(wordTable)
# now we'll count the frequencies of a set of words
# the set of words to count (package names in this case)
words <- c("'ggplot2'", "'car'", "'ggplot2'", "'lavaan'", "'cluster'", "'viridis'", "'car'", "'ggplot2'")
# reset table to start fresh, always good to do immediately before using
wordTable <- new.env()
# iterate over the words and build the hash table
for (i in words) {
if (exists(i, wordTable)) {
wordTable[[i]] <- wordTable[[i]] + 1
} else {
wordTable[[i]] <- 1
}
}
# the result (among several options)
names(wordTable) # the keys
ls.str(wordTable) # the structure, i.e., key and value of each object
# iterate over all the keys and print the values
for (i in names(wordTable)) {
cat(i, wordTable[[i]], "\n")
}