Multidimensional Sentiment Analysis (Part 1)
For the Quant UX book, Kerry Rodden and I considered writing a chapter on sentiment analysis. Ultimately we decided against it. The topic was too complex and needs almost an entire book in itself.
We realized that an introductory chapter would need to describe the foundations of text mining along with natural language processing and dictionaries, before turning to the topic of sentiment analysis, how to perform it in R, and an explanation of the code. That is too much for one chapter! And most of that is covered in other sources, such as Silge and Robinson's Text Mining with R.
In this post, I share what would have been the main point if we had written the chapter: how to use multidimensional sentiment analysis instead of typical unidimensional sentiment.
In short, this post is like a brief version of a "bonus chapter" for the book! However, rather than explaining everything, I'll go quickly and assume that you will read the code or references as needed.
Sentiment
UX, CX, and Marketing researchers often want to understand what customers are saying about a product. The best way is to develop a coding system, train raters, and then manually read and code comments. That's slow and expensive.
A more common approach is to compile hundreds or thousands of comments and automatically score them. The most common approach is to score each word and then add up the score, aka a "bag of words" method. Decoding multiword patterns is usually more work than it's worth (although that's a long discussion I'll set aside).
For example, one comment might say "I love it" and be scored +1 for sentiment (love). Another comment might say, "I absolutely hate it, it's awful, and worse than nothing." Depending on one's algorithm, that might score -1 (as being overall negative), -2 (for the words, hate + awful), -3 (hate, awful, worse), or -4 (hate, awful, worse, nothing).
Taking the average scores across many comments, and repeating that for several products, you might end up reporting something like this:

(As a reader, you know I usually share my R code. Here it is for those fake data.)
# make some fake aggregate sentiment scores for 12 products
set.seed(98101)
prod.df <- data.frame(Product = paste("Product", LETTERS[1:12]),
Sentiment = runif(12) * 200 - 100)
library(ggplot2)
ggplot(prod.df, aes(x=Product, y=Sentiment)) +
geom_col() + coord_flip() + theme_minimal()
Multidimensional sentiment
The problem with that level of sentiment analysis is that it doesn't tell us much. In the example above, products A, D, and I are highest ... but why? What's wrong with products B, E, and H?
The best way to find out more is — wait for it ... — to read the comments. However, we can extract more information algorithmically by scoring the comments for additional emotions beyond just positive and negative sentiments. That is multidimensional sentiment analysis (MDSA).
One convenient library, which is available for personal and research purposes — or licensed for commercial purposes — is the NRC Word-Emotion Association Lexicon (S. Mohammad, 2011). In addition to English, it has been translated (automatically, and at varying levels of accuracy) to 108 languages. It is a dictionary that maps 13,872 words (in English) to 10 dimensions: 8 emotions plus the generic positive and negative directions.
Here's an excerpt:

You can see that some words map to multiple dimensions, such as "abandoned" being scored as reflecting both anger and fear. The list of dimensions in the NRC dictionary is:
Anger
Anticipation
Disgust
Fear
Joy
Negative
Positive
Sadness
Surprise
Trust
Given this dictionary, we can now ask questions like:
Our product's sentiment is positive ... but are users delighted? ("joy" and "surprise") Or is it just generically and mildly positive?
If our product's score is negative ... is it modestly negative or do they hate it?
Which users are actively angry? Which ones talk about trust?
We have ratings for our products and competitors' products ... how do the products cluster in emotional space?
To do that, we score all of the comments on all of the 10 emotional dimensions and examine the patterns. Following is an example.
Example text analysis
A good way to practice text analytics is to use open-source texts. Project Gutenberg (which has digitized versions of older books) is a great source. In this section, I'll take a look at six works by Shakespeare: five plays (Hamlet, Henry V, King Lear, A Midsummer's Night Dream, and Much Ado about Nothing) plus the Sonnets.
At the end of this post, I share R code that (1) downloads those six works of Shakespeare (or anything else from Project Gutenberg); (2) scores them for multidimensional sentiment; and (3) plots the result. I won't step through all of the code for two reasons. First, for readers with basic fluency in R, the code is fairly straightforward and documented inline. Second, as noted in the introduction above, the overall topic requires substantial explanation and I leave that to the references below.
To be clear, I am not analyzing the Shakespeare texts as literature. Rather, I treat them as proxy texts that are somewhat similar to potential user comments about products. You can pretend that "Hamlet" is a product, and the "hamlet" text lines are a set of user comments about it. Similarly, "lear" is a set of comments about a different product, and so forth. The goal is to collect a somewhat realistic and moderately sized set of text that we can use for practice and see how MDSA works.
The R code is in the appendix below, and I'll point out a few features of it. First, I wrote a function "readGutenberg()" that downloads a text from a Project Gutenberg URL and performs basic cleanup. It is used to load the texts like this:
hamlet.file <- readGutenberg("https://www.gutenberg.org/files/1524/1524-0.txt", sourcename = "Hamlet")
In particular, the readGutenberg() function assumes that successive lines from one speaker are part of a continuous "comment" and combines them into a single line. That gives an R object with lines of raw text as in the following screenshot. This shows the tail() , i.e., lines 1409-1413 of Hamlet:

Second, the R code uses the NRC Lexicon to find the bag-of-words multidimensional emotion scores for each set of text lines. In the code, there is a function score.dims() as shown here. This is a screenshot of the partial output as the function runs (I always like my code to show progress):

The function returns scores for each line as shown in the next screenshot. This shows the scores for 10 random lines from the various works. You can see that they range from no particular emotion (five of the lines that are all zero) to complex mixtures of emotions. The latter may come from lengthy lines or soliloquies.

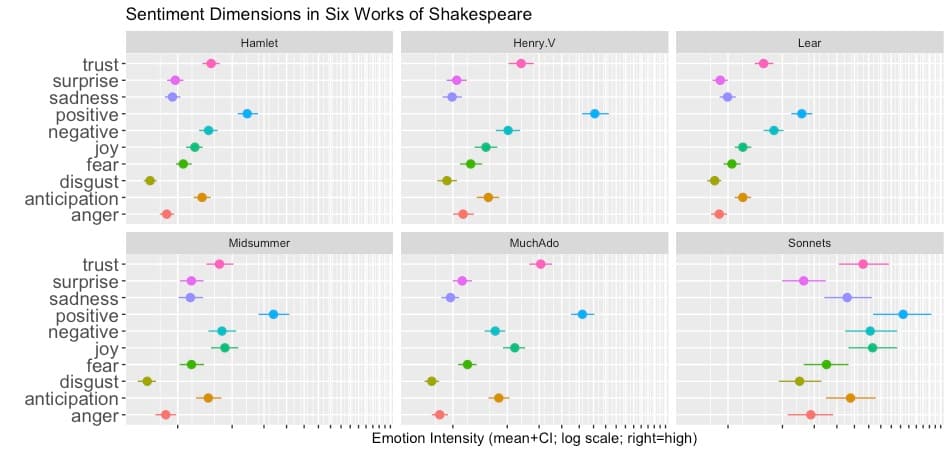
Third, the code plots the emotional dimensions by work. Here's the result:

I have a few notes about this chart. First, in terms of scaling, you'll notice the log scaling on the X axis. Most of the works use emotions sparingly on a per-word and per-line basis, and a logarithmic scale helps to display the relative frequencies.
Second, we see patterns that make sense for the Shakespearean works:
Midsummer and Much Ado have higher positive sentiment than Hamlet and Lear (no surprise!)
Emotions are overall much more prominent in the Sonnets (also no surprise)
The theme of trust is strong in Henry V and Much Ado
... and so forth
Isn't that much more informative than simple positive and negative sentiment? Give such scores — if they were user comments — we could then do things like identify the comments that reflect anger and read them; look at comments that show delight; and so forth.
For instance, suppose we want to review the top 5 most "angry" comments. We can order the sentiments with order(shake.sent$anger, decreasing=TRUE), select the top 5 using [1:5], and get the relevant lines from the data (shake.df$Line):
shake.df$Line[order(shake.sent$anger, decreasing=TRUE)[1:5]]
Sure enough, the quotes are quite long. That poses the question of whether we should normalize the sentiment by the length of the line (perhaps log(nchar()) would work?), or the relative degree of a unique emotion, rather than the raw counts. It all depends on your question and how you consider the user comments; perhaps longer comments are more useful.
Here's the top "angry" comment, from Hamlet (remember that the readGutenberg() function combines lines from a single speaker into a single "comment"; I've broken it into a few paragraphs and reduced the capitalization):
HAMLET. Ay, so, God b’ wi’ ye. Now I am alone.
O what a rogue and peasant slave am I!
Is it not monstrous that this player here, but in a fiction, in a dream of passion, could force his soul so to his own conceit that from her working all his visage wan’d; tears in his eyes, distraction in’s aspect, a broken voice, and his whole function suiting with forms to his conceit?
And all for nothing! For Hecuba? What’s Hecuba to him, or he to Hecuba, that he should weep for her? What would he do, had he the motive and the cue for passion that I have?
He would drown the stage with tears and cleave the general ear with horrid speech; make mad the guilty, and appal the free, confound the ignorant, and amaze indeed, The very faculties of eyes and ears.
Yet I, A dull and muddy-mettled rascal, peak like John-a-dreams, unpregnant of my cause, and can say nothing. No, not for a king ipon whose property and most dear life a damn’d defeat was made.
Am I a coward? Who calls me villain, breaks my pate across? Plucks off my beard and blows it in my face? Tweaks me by the nose, gives me the lie i’ th’ throat as deep as to the lungs? Who does me this? Ha! ’Swounds, I should take it: for it cannot be but I am pigeon-liver’d, and lack gall to make oppression bitter, or ere this I should have fatted all the region kites with this slave’s offal.
Bloody, bawdy villain! Remorseless, treacherous, lecherous, kindless villain! Oh vengeance! Why, what an ass am I! This is most brave, that I, the son of a dear father murder’d, prompted to my revenge by heaven and hell, must, like a whore, unpack my heart with words and fall a-cursing like a very drab, a scullion! Fie upon’t! Foh! About, my brain!
I have heard that guilty creatures sitting at a play, have by the very cunning of the scene, been struck so to the soul that presently they have proclaim’d their malefactions. For murder, though it have no tongue, will speak with most miraculous organ.
I’ll have these players play something like the murder of my father before mine uncle. I’ll observe his looks; I’ll tent him to the quick. If he but blench, I know my course. The spirit that I have seen may be the devil, and the devil hath power t’assume a pleasing shape, yea, and perhaps out of my weakness and my melancholy, as he is very potent with such spirits, Abuses me to damn me. I’ll have grounds more relative than this.
The play’s the thing Wherein I’ll catch the conscience of the King.
Indeed, in this scene, Hamlet is angry! (Geek note: Star Trek TOS fans will recall that this scene appears in the "Conscience of the King" episode.)
Given the multiple dimensions, is there more we can do? Yes! ... And for that, stay tuned for a Part 2 post (or see the first reading suggestion below).
Further reading
First, stay tuned! As noted above, I'll follow up with a Part 2 post showing other ways that multidimensional sentiment analysis can be useful.
Meanwhile, here are other suggested readings:
For a summary of use cases and business questions for text analytics — plus brief discussion of validity and ethics concerns — see my 2020 commentary in the Journal of Marketing; the article is available freely. BTW, it uses the same Shakespeare example; I repurposed the code here.
A complete discussion of text mining for marketing applications is the premier article in the same issue of the Journal of Marketing: Berger, Humphreys, Ludwig, Moe, Netzer, and Schweidel (2020), "Uniting the Tribes: Using Text for Marketing Insight." My commentary in the bullet above reflects on their article.
The NRC lexicon and emotional sentiment dictionary from Saif Mohammad are available here.
All the fundamentals, concepts, and basic jargon of text analytics are presented in Silge and Robinson's book, Text Mining with R: A Tidy Approach.
Code Appendix
This is an excerpt of code used and referenced in my article (see Further reading above):
Chapman, C (2020), "Mind your text for marketing practice", Journal of Marketing 84:1.
To use the code:
Copy the code over to R (click the "copy" button in the upper right; then paste to RStudio etc.)
Install any of the required R packages you might need:
plyr,dplyr,tidytext,ggplot2, andtextdata.Step through the code line-by-line and read the comments for explanations. Notes:
It requires Internet access to download the lexicon and example texts.
The NRC lexicon is licensed for free only for non-commercial purposes. See the author's site for options on commercial licenses available from the Government of Canada.
# Excerpt for blog, part 1 of sentiment analysis code
# Complete code is at:
# http://r-marketing.r-forge.r-project.org/misc/shakespeare-sentiment-example.R
#
# Author: Chris Chapman
# Content: R analysis snippets to accompany
# Journal of Marketing commentary,
# "Mind your text for marketing practice".
# License: CC By 4.0 (Creative Commons International Attribution 4.0)
# https://creativecommons.org/licenses/by/4.0/
# Briefly: free to use for any purpose if a citation is given.
# There is no express or implied warranty of any kind.
#
# CITATION: Chapman, Chris (2020). "Mind your text for marketing practice".
# Journal of Marketing, January 2020.
###
### OVERVIEW
###
# The code here recreates two example analyses, using works of Shakespeare
# as example texts. The overall flow is:
#
# PART 1, Here:
# 1. read the example texts and compile a corpus
# 2. code them for multidimensional sentiment using NRC sentiment dimensions
# 3. examine the sentiment by work
#
# PART 2, Forthcoming:
# 4. create a composite perceptual map of the sentiment dimensions
#
# TO USE IT:
# 1. Install the prerequisite packages as they appear
# 2. Step through the lines to go through the analyses
#
# NOTE: ===> Important comments and discussion are embedded throughout.
#
####
# FUNCTION readGutenberg()
#
# a helper function to get files from Project Gutenberg and compile paragaphs
# into individual lines. note that it leaves in all lines between the
# "start" and "end" markers, which includes title, authors, section headers,
# and so forth.
#
# REQUIRES: internet connectivity that can see www.gutenberg.org
#
# DISCUSSION
# For the most robust usage, you would want more error checking, for example
# to handle lack of internet connectivity
#
readGutenberg <- function(urlIn, sourcename="source") {
# open the URL and read all the lines
con <- url(urlIn)
text <- readLines(con)
close(con)
linein <- ""
result <- rep("", length(text)) # hold results
counter <- 1
intext <- FALSE
for (i in seq_along(text)) {
if (intext) {
if (nchar(text[i]) > 0) {
if (grepl("end", text[i], ignore.case = TRUE) &
grepl("gutenberg", text[i], ignore.case = TRUE)) {
intext <- FALSE
} else {
linein <- paste(linein, text[i])
}
} else {
if(nchar(linein) > 0) {
result[counter] <- linein
counter <- counter + 1
linein <- ""
}
}
} else {
if (grepl("start", text[i], ignore.case = TRUE) &
grepl("gutenberg", text[i], ignore.case = TRUE)) {
intext <- TRUE
}
}
}
result <- result[1:counter] # trim the trailing blanks for combined lines
result <- data.frame(Line=result, stringsAsFactors = FALSE)
result$Source <- sourcename
return(result)
}
# get six Shakespeare works
# note: internet connection is required
hamlet.file <- readGutenberg("https://www.gutenberg.org/files/1524/1524-0.txt", sourcename = "Hamlet")
midsum.file <- readGutenberg("https://www.gutenberg.org/files/1514/1514-0.txt", sourcename = "Midsummer")
lear.file <- readGutenberg("https://www.gutenberg.org/files/1532/1532-0.txt", sourcename = "Lear")
sonnets.file <- readGutenberg("https://www.gutenberg.org/ebooks/1041.txt.utf-8", sourcename = "Sonnets")
muchado.file <- readGutenberg("https://www.gutenberg.org/ebooks/1118.txt.utf-8", sourcename = "MuchAdo")
henryv.file <- readGutenberg("https://www.gutenberg.org/files/1521/1521-0.txt", sourcename = "Henry.V")
# compile them into a standard data frame marked with the sources
shake.df <- rbind(hamlet.file, midsum.file, lear.file, sonnets.file,
muchado.file, henryv.file)
shake.df$Source <- factor(shake.df$Source)
summary(shake.df$Source)
### SENTIMENT ANALYSIS
###
### REQUIRES: prior installation of packages: plyr, dplyr, tidytext, ggplot2
### "textdata" package to get sentiments
###
library(plyr)
library(dplyr)
library(tidytext)
library(ggplot2)
# NOTE: the NRC dictionary must first be downloaded interactively
# in the command prompt, issue the following:
textdata::lexicon_nrc() # requires internet connection
# DISCUSSION:
# In real usage, you would want to do more to construct a useful
# dictionary. For instance, if we were *really* interested in Shakespeare,
# we would want to score the many unique/archaic words and contractions
# that appear uniquely in Shakespeare. As mentioned in the JM commentary
# article, it is important to check a dictionary for your domain.
#
# In the present case, we are interested in a (relatively) minimal
# demonstration, so we simply use the NRC dictionary as is. But you
# should use caution before simply applying it as is to new data.
# FUNCTION score.dims()
#
# a function that will score lines with the 10 dimensions in NRC data.
# Note that NRC_EIL is a more recent dictionary than NRC, with degree coded
# in addition to the emotional direction. We use NRC here for simplicity.
#
# DISCUSSION:
# In real usage, you would want to do more pre-processing, such as
# removing stop words and possibly stemming and/or handling contractions.
# Details would depend on the sentiment dictionary you are using.
# For this demonstration example, we simply process the text as is.
#
score.dims <- function(text.vec, silent=FALSE) {
library(plyr)
library(dplyr)
library(tidytext)
# get the multidimensional NRC dictionary
# citation:
# Saif Mohammad (2011), NRC Word-Emotion Association Lexicon
# http://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm
my.sent.nrc <- get_sentiments("nrc")
my.sent.nrc$sentiment <- factor(my.sent.nrc$sentiment)
# FUNCTION score.dim()
# Scores a single line of text. Called only by the outer function.
#
# DISCUSSION: this is where you might handle more text clean up, such as
# handling stop words or excluding irrelevant words that might mislead
# the dictionary scoring in your domain.
#
score.dim <- function(text.vec) {
text.words <- data.frame(word=tolower(unlist(strsplit(text.vec, " "))))
text.tab <- table(na.omit(join(text.words,
my.sent.nrc, by="word")$sentiment))
return(rbind(c(text.tab))) # give it as a row suitable to add to a df
}
# set up a place to hold the results and then iterate over all comments
#
# DISCUSSION
# I use rbind() here to add one result at a time, but this is
# inefficient and slow in R. It is OK for small data sets, such as the
# present data. For large data sets, it would be better to pre-allocate
# a matrix of the maximum size we expect, so it is only allocated a single
# time. Then fill in the rows with the line-by-line results.
#
hats.sent.dim <- NULL
for (i in seq_along(text.vec)) {
line <- text.vec[i]
hats.sent.one <- score.dim(line)
# see note above about efficiency of rbind(). I use it here for
# simplicity of the code example, but pre-allocation would be better
# for larger data sets
hats.sent.dim <- rbind(hats.sent.dim, hats.sent.one)
if (!silent & i %% 100 == 0 ) { # show progress
cat(i, " : ", hats.sent.one, " : ", line, "\n")
}
}
hats.sent.dim <- data.frame(hats.sent.dim)
return(hats.sent.dim)
}
### SLOW: processes and scores every line ===>
shake.sent <- score.dims(shake.df$Line) # score the text
shake.sent$Work <- shake.df$Source # add back in the source
summary(shake.sent)
# Plot sentiment by Work
library(reshape2)
shake.sent.m <- melt(shake.sent)
# add small constant so we can do plot with log transform and avoid 0
shake.sent.m$value <- shake.sent.m$value + 0.01
library(car) # for some() function
some(shake.sent.m, 20)
library(ggplot2)
library(Hmisc) # for mean + CI estimation
p <- ggplot(data=shake.sent.m, aes(x=variable, y=value, colour=variable)) +
stat_summary(fun.data = "mean_cl_boot") +
scale_y_log10(minor_breaks = seq(0, 1, 0.01), breaks = seq(0, 1, 0.025)) +
xlab("") +
ylab("Emotion Intensity (mean+CI; log scale; right=high)") +
facet_wrap(facets = vars(Work)) +
theme(legend.position="none") +
theme(axis.text.y = element_text(size=14)) +
theme(axis.text.x = element_blank()) +
coord_flip() +
ggtitle("Sentiment Dimensions in Six Works of Shakespeare")
p